
북마크 룩업
Index Scan과 Index Seek에서 Scan을 사용하면 일반적으로 나쁜것이지만 항상 나쁜것은 아니다.(찾으려는 데이터를 order by했을 경우) 또, Seek를 사용하면 일반적으로 좋지만 항상 좋은것은 아니다.
그런데 의문은 빨리 찾기 위해 인덱스를 활용하는데 어떻게 느릴 수가 있을까??
Clustered와 NonClustered는 큰 차이점이 Leaf Page에 실질적인 데이터가 있고 없고의 차이가 있다.
그렇기 때문에 Clustered의 경우 Index Seek가 느릴 수가 없다.
하지만 NonClustered의 경우 데이터가 Leaf Page에 없으므로 한번더 타고 가야한다.
1. RID -> Heap Table을 찾아가는 것
2. Key -> Clustered를 찾아가는 것
여기서 1번이 Bookmark Lookup이다. 그렇기 때문에 Index Seek에서 Bookmark Lookup을 하는 과정에서 "비효율적"을 동작할 "가능성"이 있다는 의미이다. 오히려 그런 경우는 Index Scan이 조금 더 빠를 수 있다.
테스트를 해보자.
SELECT *
INTO TestOrders
FROM Orders;
CREATE NONCLUSTERED INDEX Orders_Index01
On TestOrders(CustomerID);
-- 조회
DBCC IND('Northwind', 'TestOrders', 2);
-- 구조
-- 1056
-- 960 968 969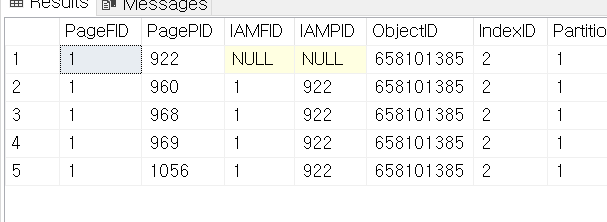
분명 HeapTable이 존재할 것이다.
SET STATISTICS TIME ON;
SET STATISTICS IO ON;
SET STATISTICS PROFILE ON;
-- 기본 탐색을 해보자.
SELECT *
FROM TestOrders
WHERE CustomerID = 'QUICK';
결과를 확인해보면 우리가 NonClustered 인덱스를 사용했는데도 불구하고 Index Seek를 사용하지 않고 Index Scan을 사용한 것을 확인할 수 있다. 기본적으로 데이터베이스에서 Scan을 하는게 조금 더 빠르다고 생각했기 때문이다.
SELECT *
FROM TestOrders WITH(INDEX(Orders_Index01))
WHERE CustomerID = 'QUICK';
인덱스를 강제적으로 사용해 Index Seek 버전으로 하니 오히려 연산의 결과가 10번정도 추가됐다.
결론적으로 인덱스를 항상 사용하는것이 올바른 경우는 아니다.
만약 조건이 2개 이상이면 어떨까?
룩업을 줄이기 위해서는 크게 두가지의 노력이 있는데
첫 번째는 삽입, 삭제, 수정이 빈번하게 발생하지 않는다면 NonClustered를 조건 2개로 하면 된다. 장점으로는 빠르게 서치할 수 있지만 데이터를 삽입하거나 삭제, 수정하는 부분에서 느리게 동작한다.
두 번째는 Index를 생성할 때 Include를 이용해 Leaf Page에 힌트만 남기는 경우다.
이 경우에도 문제를 해결할 수 없다면 Clustered Index를 활용을 고려할 수 있다.
하지만 Clustered Index는 테이블당 1개만 사용할 수 있다.
다시한번 말하지만 NonClustered Index가 악영향을 주는 경우는 북마크 룩업이 심각한 부하를 야기할 때 발생한다.
Nested Loop 조인
조인에 대해 좀 더 자세히 알아보자. join은 여러 테이블을 다루기 매우 쉬웠다. 내부적으로 처리를 어떻게 하는지 알아야 나중에 성능을 분석하는데 유리하다.
조인은 3가지 조인이 있다.
1. Nested Loop 조인
2. Merge 조인
3. Hash 조인
첫 번째 NL에 대해 알아보자.
NL을 이해하기 위해서는 C#코드로 표현해보는것이 가장 직관적이다.
전체적으로 나타내지 않고 그냥 말로 표현해보겠다.
List<player> 가 있고 List<item> 가 있다고 해보자. 이때 각 player, item에는 id가 들어 있다고 할 때 playerid 와 itemid가 동일한 정보만 추출한다고 하면 어떻게 할 수 있을까??
구현 방법에는 여러가지가 있지만 여기서 가장 직관적으로 생각할 수 있는 것은 바로 이중 for문을 돌아서 playerid == itemid 형태로 찾아서 결과를 저장할 것이다.
이게 이게 기본적인 NL의 원리이다. 물론 list로 되어있기 때문에 시간복잡도가 N^2이기 때문에 매우 느리기에 Dictionary같은 자료구조를 사용해서 N^2 에서 N으로 줄일 수 있다. 즉 외부 자료구조보단 내부에서 잘 처리하냐가 매우 중요한 핵심이다.
NL이 매우 유리한 조건이 있는데 바로 제한된 갯수를 추출할때 유리하다.
playerid와 itemid가 같은 사람 5명을 추출해줘. 라고 했을때는 매우 유리하다.
Merge 조인
병합 조인 또는 Sort Merge 조인 이라고도 부른다.
이것 역시 우리가 잘 아는 프로그래밍 언어로 생각하면 쉽다.
Player, Salary 클래스가 playerid를 가지고 있다고 하자. 그리고 Player와 Salary를 가지고 있는 List들을 Sort 한 후(이미 정렬되어 있으면 Skip) 병합하면 된다.
어떻게 병합을 할 수 있을까?
One-To-Many의 경우 player(outer)의 0번째 인덱스와 Salary(inner) 0번째 인덱스부터 비교를 하는데 같다면 inner 커서를 1 증가 시켜 비교하고 만약 다르다면 inner쪽이 더 작다면 inner커서를 증가, outer이 작다면 outer커서를 증가하는 식으로 진행 할 수 있을 것이다.
One to Many의 경우는 outer가 unique해야한다는 것이다. 즉, PK가 되어야한다는 것이다.
그렇지 않다면 Many To Many로 조금 느려질 것이다.
즉,
- 양쪽 집합을 Sort하고 Merge하는 방식이다.
- 이미 정렬된 상태라면 Sort는 생략한다.(특히, CLustered로 물리적 정렬된 상태라면 Best)
- 정렬할 데이터가 너무 많으면 매우 비효율적이다 -> Hash
- Random Access 위주로 수행되진 않는다.
- Many-to-Many 보다는 One-to-Many 조인에 효과적
- PK, Unique
'Unity > 온라인 RPG' 카테고리의 다른 글
| [Unity 2D] 컨텐츠 준비 - MapManager, Controller 정리, ObjectManager (1) | 2024.03.04 |
|---|---|
| [Unity 2D] 컨텐츠 준비 - 세팅, MapTool, 플레이어 이동 (4) | 2024.02.28 |
| [데이터베이스] SQL 튜닝 - 인덱스 분석 (0) | 2024.02.21 |
| [데이터베이스] SQL 입문 - 정규화, INDEX, UNION, JOIN... (0) | 2024.02.20 |
| [데이터베이스] SQL 입문 - Group, 추가 삭제 갱신, subquery (0) | 2024.02.16 |