
정규화
정규화는 데이터베이스를 설계하는데 매우 중요한 개념이다. 1,2,3,4 정규화가 있지만 그 것을 알기보다는 그것을 이해하기 보단 정규화를 통 틀어서 정규화가 무엇인지 아는것이 더 중요하다. 또한 자연스럽게 설계하다보면 정규화가 되어있는 경우도 있다.
정규화를 한마디로 나타내면 테이블을 올바르게 변경하고 분할하는 것 이라고 할 수 있다. 직관적으로 이해가 되지 않을 수 있으니 예를 들어보자.
RPG를 설계한다고 해보자.

데이터베이스를 처음 만드는 사람의 공통된 문제는 데이터를 한 곳에 다 넣는 경우가 가장 많다.
위의 사진에서 문제점은 일단 인벤토리를 문자열로 저장하는 것이 문제점이다.
그래서 이것을 해결하려면 아이템 마다 고유의 아이템코드를 정한 뒤 그것을 저장하는 식으로 간다.
즉 반복되는 데이터를 세로, 행 방향으로 늘린다.
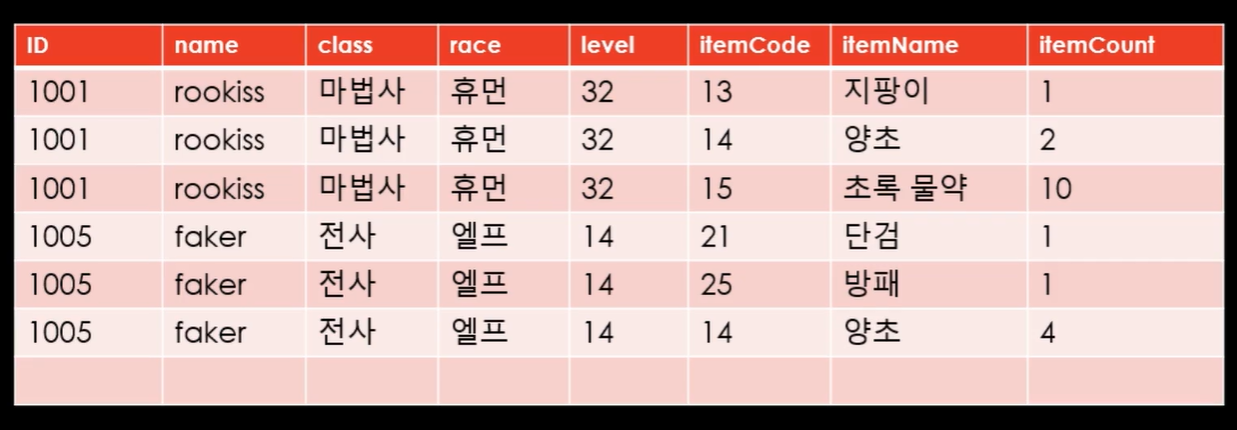
이렇게 하다보면 중복된 데이터가 너무 많이 겹치는 것을 확인할 수 있다. 유저가 100만 명이 넘는다고 생각하면 데이터 양이 너무 방대해질 것이다.
정규화에서는 데이터의 중복을 무조건적으로 줄이는 방식으로 하게된다. 그렇기에 위의 테이블을 둘로 나눈뒤 고유 키를 통해 연결해 주어야한다.

이 상태에서 보면 item에서 양초는 무조건 14번의 코드를 가질 것인데 아이템의 소유가 다르면 중복되는 현상을 확인할 수 있다.

중복을 없애는 것이 핵심이다.
INDEX
인덱스를 이해하지 못했다면 데이터베이스를 사용할 가치가 없다라고 말해도 무방하다.
우리가 책에서 특정 단어가 몇 페이지에 나오는 찾아보려면 어떻게 해야할까? 처음부터 쭉 찾아야한다. 그런데 책 후반에 INDEX를 참고하면 (키워드 색인) 몇 페이지에 나오는지 확인할 수 있다.
데이터베이스에도 동일하다. INDEX를 동록해 데이터를 빠르게 찾는 것이다. 다른 점은 이 INDEX가 변한다는 사실 뿐이다.
INDEX는 이진트리를 사용한다. 이진트리는 c++ algorithm을 페이지를 참고해라.
만약 유저가 1000명있다고 해보자. A유저가 B유저에게 귓말을 보낸다고 했을 때, 인덱스가 없다면 데이터베이스를 순차적으로 찾아야 할 것이므로 시간이 너무 오래걸릴 것이다. 그래서 인덱스를 따로 걸어두면 빠르게 찾을 수 있을 것이다.
그렇다면 인덱스를 모든 행열에 걸면 좋지 않을까???
오히려 인덱스를 걸면 손해를 보는 경우가 있다. 예를 들어 위의 데이터베이스에서 class에 색인을 걸었다고 해보자. 종류가 5가지 밖에 없으니 만약 마법사 라는 키워드로 데이터베이스를 찾았을 때 몇백명 몇천명이 나올 것이다.
즉, 색인을 한 의미가 없다.
그렇기에 데이터가 중복이 되지 않아야 효과를 볼 수 있다.

sql에는 CREATE INDEX와 DROP INDEX를 이용해 처리할 수 있다.
UNION
복수의 테이블을 다루는 방법에 다뤄보자.
관계형 데이터베이스는 데이터를 집합으로 간주하는 것이다. 서로 데이터베이스끼리 연결이 되어있으니 복수의 테이블을 다뤄보자.
커리어 평균 연봉이 3000000 이상인 선수들의 playerID 구하라
라는 문제를 풀어보자.
SELECT playerID , AVG(salary)
FROM salaries
GROUP BY playerID
HAVING AVG(salary) >= 3000000
그러면 12월에 태어난 선수들의 playerID를 구하라
는 이렇게 풀 수 있다.
SELECT playerID, birthMonth
FROM players
WHERE birthMonth = 12;
그렇다면 [커리어 평균 연봉이 3백만 이상] 이거나 [12월에 태어난] 선수의 playerID는 어떻게 추출할까
바로 UNION을 사용하면 된다.(중복은 알아서 제거된다.)
SELECT playerID
FROM salaries
GROUP BY playerID
HAVING AVG(salary) >= 3000000
UNION
SELECT playerID
FROM players
WHERE birthMonth = 12;교집합은 INTERSECT를 이용하면 된다.
차집합은 EXCEPT를 사용한다.
JOIN(결합)
USE GameDB;
CREATE TABLE testA(
a INTEGER
)
CREATE TABLE testB(
b VARCHAR(10)
)
--A(1, 2, 3)
INSERT INTO testA VALUES(1);
INSERT INTO testA VALUES(2);
INSERT INTO testA VALUES(3);
INSERT INTO testB VALUES('A');
INSERT INTO testB VALUES('B');
INSERT INTO testB VALUES('C');
-- Cross Join(교차 집합)
-- 말그대로 1 - A , 1 - B, 1 - C ...
SELECT *
FROM testA
CROSS JOIN testB;
SELECT *
FROM testA, testB;
----------------------------------
USE BaseballData;
-- INNER JOIN (두 개의 테이블을 가로로 결합 + 결합 기준을 ON으로)
SELECT *
FROM players AS p
INNER JOIN salaries AS s
ON p.playerID = s.playerID;
-- OUTER JOIN (외부 결합)
-- LEFT / RIGHT
-- 어느 한쪽에만 존재하는 데이터 -> 정책?
-- LEFT JOIN (두 개의 테이블을 가로로 결합 + 결합 기준을 ON으로)
-- playerID가 왼쪽(Left, players)에 있으면 무조건 표시, 오른쪽(salaries)에 없으면 오른쪽 정보는 NULL로 채움
SELECT *
FROM players AS p
LEFT JOIN salaries AS s
ON p.playerID = s.playerID;
-- RIGHT JOIN (두 개의 테이블을 가로로 결합 + 결합 기준을 ON으로)
-- playerID가 오른쪽(RIGHT, salaries)에 있으면 무조건 표시, 왼쪽(players)에 없으면 오른쪽 정보는 NULL로 채움
SELECT *
FROM players AS p
RIGHT JOIN salaries AS s
ON p.playerID = s.playerID;TRANSACTION
-- BEGIN TRAN;
-- COMMIT;
-- ROLLBACK;데이터 베이스를 갱신할 때 꼭 하나의 테이블만 갱신하는게 아니라 두개 이상 갱신하고 싶을 때가 있다.
근데 만약 A 테이블에 insert에 실패했는데 B는 성공했다고 하면 문제가 발생할 것이다.
즉, ALL or NOTHING인 것이다.
모두 일어나거나 아무것도 일어나지 않아야한다.
우리가 INSERT 할 때 TRAN을 명시하지 않으면 자동으로 COMMIT이 된다.
그 때 우리가 TRAN을 명시하게 되면 COMMIT을 하거나 ROLLBACK을 선택 하는 것이다.
BEGIN TRAN을 하면 아직 insert가 임시 공간에 묶이게 되고 여러 insert가 끝난 후 commit을 통해 적용하거나 rollback을 통해 되돌아가는것이다.
BEGIN TRAN;
INSERT INTO accounts VALUES(2,'minseok', 100, GETUTCDATE())
ROLLBACK;
BEGIN TRAN;
INSERT INTO accounts VALUES(2,'minseok', 100, GETUTCDATE())
COMMIT;
-- 응용
BEGIN TRY
BEGIN TRAN;
INSERT INTO accounts VALUES(1,'minseok', 100, GETUTCDATE());
INSERT INTO accounts VALUES(2,'minseok2', 100, GETUTCDATE());
COMMIT;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0 -- 현재 활성화 된 트랜잭션 수를 반환
ROLLBACK
END CATCH주의할 점은 딱 하나이다.
TRAN 안에는 꼭!!!!! 원자적으로 실행할 애들만 넣어야 한다.
그 이유는 성능상의 이유이다.
우리가 C#에서 원자적으로 수정하기 위해서는 lock을 잡고 실행했었다.
그것과 마찬가지로 sql에서도 lock을 잡기 때문에 TRAN안에 있는 작업이 완료되지 않으면 다른 쿼리가 동작하지 않고 기다리게 된다. 그렇기 때문에 TRAN안에는 연산이 빨리 끝나는 동작만, 그리고 원자적으로 실행해야하는 동작만 넣어 최소화 하는게 좋다.
변수와 흐름 제어
-----------변수---------
-- 변수 선언
DECLARE @i AS INT = 10;
DECLARE @j AS INT;
SET @j = 10;
-- 예제 ) 역대 최고 연봉을 받는 선수 이름 저장?
DECLARE @firstName AS NVARCHAR(15);
DECLARE @lastName AS NVARCHAR(15);
SET @firstName = (SELECT TOP 1 *
FROM players AS p
INNER JOIN salaries AS s
ON p.playerID = s.playerID
ORDER BY s.salary DESC);
-- 또는
SELECT TOP 1 @firstName = p.nameFirst, @lastName = p.nameLast
FROM players AS p
INNER JOIN salaries AS s
ON p.playerID = s.playerID
ORDER BY s.salary DESC;
-----------배치(batch)---------
-- {}와 동일한 역할
GO
-- 배치를 이용해 변수의 유효범위 설정 가능 { }
DECLARE @i AS INT = 10;
-- 배치는 하나의 묶음으로 분석되고 실행되는 명렁어 집합
-----------흐름 제어---------
-- IF
GO
DECLARE @i AS INT = 10;
IF @i = 10
PRINT('BINGO!');
ELSE
PRINT('NO');
IF @i = 10
BEGIN
PRINT('BINGO!');
PRINT('BINGO!');
END
ELSE
BEGIN
PRINT('NO');
END
--WHILE
GO
DECLARE @i AS INT = 0;
WHILE @i <= 10
BEGIN
PRiNT @i;
SET @i = @i + 1;
IF @i = 6 BREAK;
-- IF @i = 6 CONTINUE;
END
-----------테이블 변수---------
-- 임시로 사용할 테이블을 변수로 만들 수 있다!
-- testA, testB 만들고 삭제 -> NO!
-- DECLARE를 사용 -> tempdb 데이터베이스에 임시 저장되고 삭제되는 형식
GO
DECLARE @test TABLE
(
name VARCHAR(50) NOT NULL,
salary INT NOT NULL
);
INSERT INTO @test
SELECT p.nameFirst + ' ' + p.nameLast, s.salary
FROM players AS p
INNER JOIN salaries AS s
ON p.playerID = s.playerID;
SELECT *
FROM @test
윈도우 함수
윈도우 함수는 행들의 서브 집합을 대상으로, 각 행별로 계산해서 스칼라(단일 고정) 값을 출력하는 함수를 의미한다.
느낌상 GROUPING이랑 비슷한 느낌이난다. 다른점은 GROUP BY 같은 경우 집계함수와 그룹으로 묶은 컬럼만 사용이 가능하다는 점이 다르다.
전체 데이터를 연봉 순서로 나열하고, 순위를 표시해보자.
-- ~OVER([PARTITION] [ORDER BY] [ROWS])
SELECT *,
ROW_NUMBER() OVER (ORDER BY salary DESC), -- 행#번호
RANK() OVER (ORDER BY salary DESC), -- 순위
DENSE_RANK() OVER (ORDER BY salary DESC), -- 동점자 랭킹 처리
NTILE(100) OVER (ORDER BY salary DESC) -- 상위 몇 %
FROM salaries;
그럼 playerID 별 순위를 따로 하고 싶다면??
SELECT * ,
RANK() OVER (PARTITION BY playerID ORDER BY salary DESC)
FROM salaries
ORDER BY playerID;
추가적으로 LAG와 LEAD는 자주 사용하니 알아보자. LAG는 바로 이전 값을 의미 하고, LEAD는 바로 다음을 의미한다.
SELECT * ,
RANK() OVER (PARTITION BY playerID ORDER BY salary DESC),
LAG(salary) OVER (PARTITION BY playerID ORDER BY salary DESC) AS prevSalary,
LEAD(salary) OVER (PARTITION BY playerID ORDER BY salary DESC) AS nextSalary
FROM salaries
ORDER BY playerID;
'Unity > 온라인 RPG' 카테고리의 다른 글
| [데이터베이스] SQL 튜닝 - 북마크 룩업, Join, Sorting (1) | 2024.02.23 |
|---|---|
| [데이터베이스] SQL 튜닝 - 인덱스 분석 (0) | 2024.02.21 |
| [데이터베이스] SQL 입문 - Group, 추가 삭제 갱신, subquery (0) | 2024.02.16 |
| [데이터베이스] SQL 입문 - DATETIME, CASE, 집계 함수 (0) | 2024.02.14 |
| [데이터베이스] SQL 입문 - SSMS 다루기와 각종 문법 (2) | 2024.02.14 |